
数据的标准化就是将数据按照比列缩放,使之落入一个小的特征区间。
在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权
最典型的就是数据的归一化处理,即将数据统一映射到【0,1】区间上.
举例:
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt'''方法:极差标准化极差标准化是一种常见的数据标准化方法,它通过将原始数据按极差进行缩放,使得不同取值范围的数据具有统一的取值范围,以便于统计和运算处理。将数据的最大最小值记录下来,并通过max-min作为基数,(即min=0,max=1)进行数据的归一化处理x = (x - min) / (max - min)原数据减去最小值除以(最大值减最小值)'''df = pd.DataFrame({'value1':np.random.rand(10)*20, 'value2':np.random.rand(10)*100})def guiyi(data, *cols): df_n = data.copy() #对大量数据进行处理的时候,一般先copy一个数据。 for col in cols: ma = df_n[col].max() mi = df_n[col].min() df_n[col+'_n'] = (df_n[col] - mi) / (ma - mi) return(df_n)df_n = guiyi(df,'value1', 'value2')df_n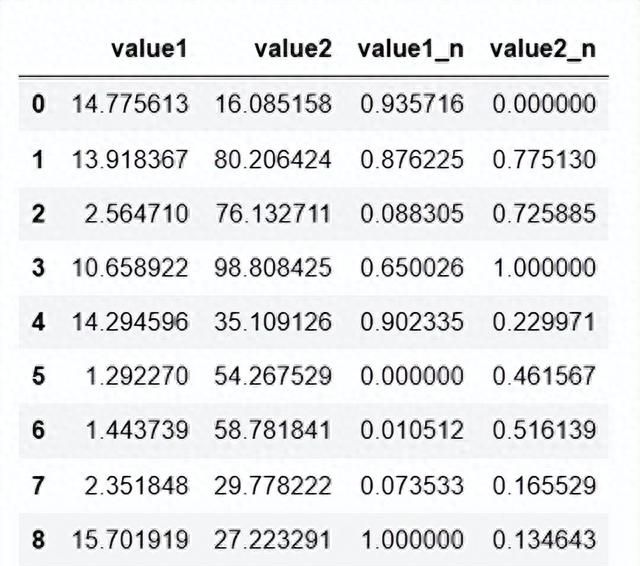
第二种数据标准化处理方法:Z-SCORE标准化
z分数 是一个分手与平均数的差再除以标准差的过程–z=(x-u)/σ, 其中x为某一具体分数,u为平均数,σ为标准差,
Z值的量代表着原始分数和母体平均值之间的距离,是以标准差为单位计算。在原始分数低于平均值时Z则为负数,反之则为正数。
数学意义:一个给定分数距离平均数多少个标准差
公式:(df['data'] – df['data'].mean()) / df['data'].std()
df = pd.DataFrame({'value1':np.random.rand(10)*100, 'value2':np.random.rand(10)*100})dfdef z_score(df, *cols): df_n = df.copy() for col in cols: u = df_n[col].mean() std = df_n[col].std() df_n[col+'_zn'] = (df_n[col] - u) / std return(df_n)df_n = z_score(df, 'value1', 'value2')df_n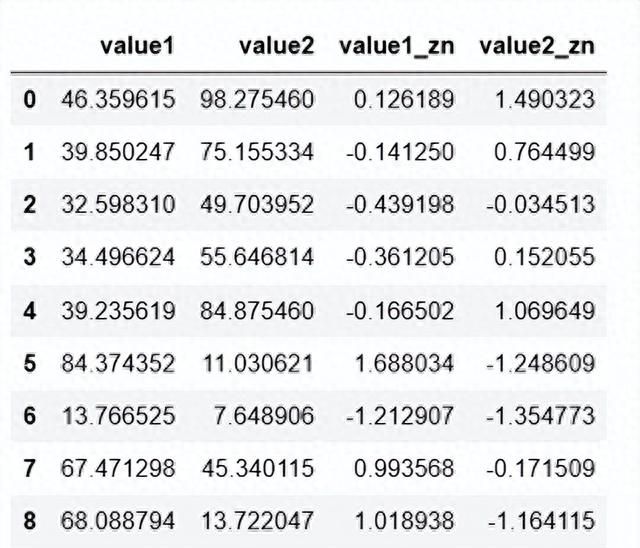
经过处理的数据符合标准正态分布,即均值为0,标准差为1.
df_n value1_zn 中的数值代表集中趋势离平均数标准差的个数,标准化后的值越大,代表这个数据距离他的平均数越远,值越小,代表越近。
那么什么情况下我们会用到z-score标准化呢?
一般在分类,聚类算法中,需要使用距离来度量相似性的时候,z-score表现更好。比如两组数据判断相似性的时候。

声明:本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。E-MAIL:dandanxi6@qq.com
