
练武的人都知道:练武不练功,到老一场空!
说的是只练花架子,不练习内功,最终也都是一个菜鸟级武师。


学习编程何尝不是!我时常见到已经学习相当一段时间的程序员,连稍微深点的基本知识都没有掌握。可叹,可悲啊!根子不牢,注定走不远啊!
基于实例学习编程非常重要,也非常有效,但与此同时,我们也必须不断的加强基本功的学习,刻意的加强相关的技术。掌握技术脉络,加强各项技术,跳出编程语言本身,练好内功,才能爬的又快又好,成为一个高级的爬虫工程师!

本文从爬虫的技术原理出发,讨论了Python爬虫工程师必须掌握和不断加强的几项技术。
技术脉络
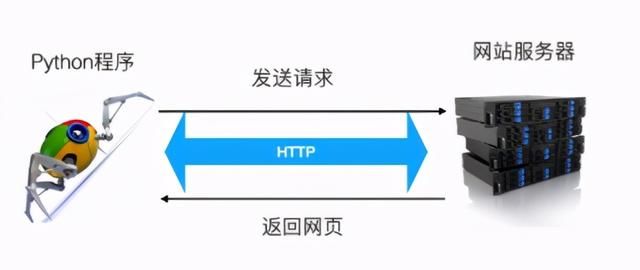
- 程序发送请求给网页服务器,请求基于HTTP协议。
- 服务器返回网页或者数据,格式为HTML,JSON,XML等。
- 程序从HTML,JSON,XML等文本中解析返回的网页,用的技术包括xpath, 正则表达式,css选择器等。
- 程序把解析好的保存到文件或者数据库中供后续分析使用。文件格式通常是cvs,数据库可以使用关系型数据库如MySQL,或者非关系型数据库如MongoDB。
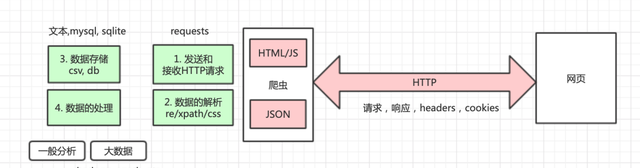
除此之外,网站会有各种反爬取技术,爬虫工程师和网站开发工程一个攻,一个守,斗智斗勇。
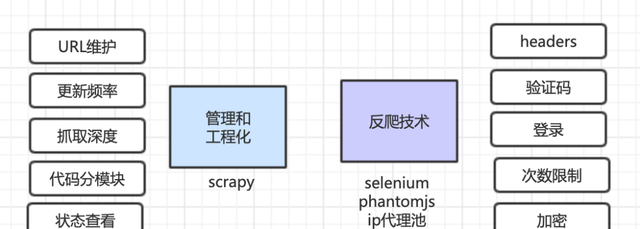
另外,爬虫10个网页和爬取10000个网站是不同的概念,你需要维护要爬取的数以万计的URL,设置更新频率,去掉不需要的URL等等,查看各个网站的爬取状态等,这就是一个工程化的问题。商业级的爬虫涉及到很多工程化问题。
就像家庭作坊可以就在自己院子里,一家人就能生产出少量的产品。但要大量生成就需要厂房,财务,人事等企业框架和管理制度、
Python爬虫工程师的修养
下面列举了爬虫工程师需要不断掌握和精进的基本功技术:
HTTP协议
HTTP协议是爬虫和网页交流的语言,如果不懂这个语言,你肯定不能成为一个有效的爬虫工程师。你也不需要成为一个协议专家,主要掌握请求,相应,header,COOKIE等就可以了。

网页格式:HTML和CSS
我们看到的网页基本都是HTML的格式,我们要从HTML的脚本中找出所需要的信息,就必须掌握HTML的格式。

同样的一个HTML页面,我们可以展现不同的样式。我们通过CSS来指定样式,比如指定表格用什么背景颜色,文字用什么字体等。
这些样式,本来不是爬虫工程师在意的事情,因为我们只在意数据。但是通过CSS,我们可以有效的定位到某些数据,所以CSS还是需要学习的,后面的数据解析部分会再次提到CSS。
网页格式:Javascript
HTML是完全静态的网页,为了在网页上实现动态效果,就有了Javascript。很多网页上的数据并没有直接在HTML中给出,而是通过Javascript后续又加载出来的。
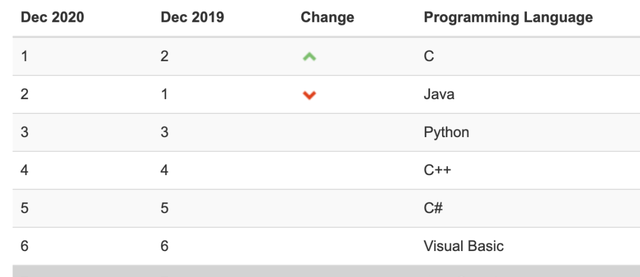
实际上,Javascript是编程语言排行榜上很靠前的编程语言,所谓的前端开发者需要精通Javascript,而爬虫工程师了解基本的知识,知道Ajax请求的相关原理,有时候还要知道如何用Javascript加密,就差不多了。
网页格式:JSON
JSON是Javascript Object Notation的意思,可以理解成一种数据结构。一般的数据API都是以JSON格式的:

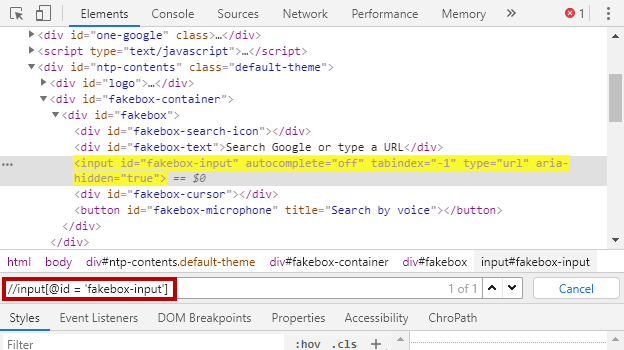
数据解析 – xpath
我们需要用某种技术,从HTML中找出我们想要的数据,xpath是其中一种。简单说,就是通过路径来找到想要的数据:
数据解析 – css选择器
通过指定样式,我们也可以定位到指定的数据,再解析数据:
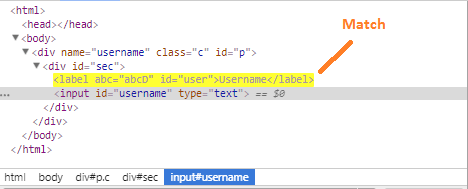
因为喜欢Jquery的原因,我个人更喜欢CSS选择器。
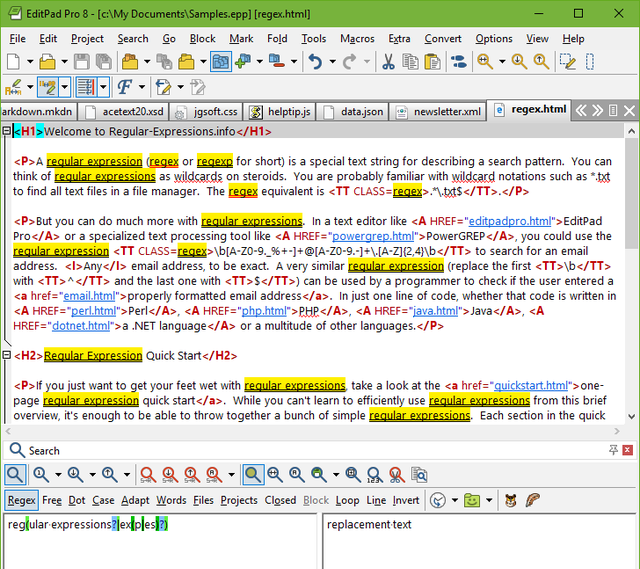
数据解析 – 正则表达式
前两种数据解析都是基于结构的解析方式,而正则表达式(re)就把HTML当成一个文本,不在意其中的结构,用字符串的规则解析数据:
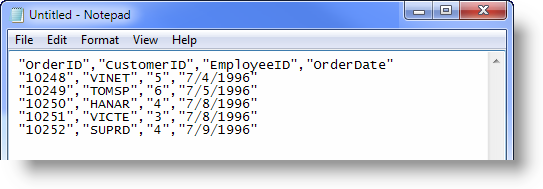
数据存储 – csv
CSV是用逗号隔开的一种纯文本的数据格式,是数据分析和处理中最常用的格式。CSV可以用记事本打开,也可以用Excel打开。
数据存储 – 数据库
把数据存储在CSV等文本中很方便,但是数据的查询和处理不方便,为了解决这个问题,我们可以会把数据保存在数据库中。
这是很广阔的领域,数据库是计算机技术中最重要分分支之一。值得你不断地学习和精进。相比前面的HTML等,你只要几个小时就可以学会了,后面也不怎么需要更新知识。

反爬技术 – ocr, selenium等
关于反爬技术,请看我另外一篇文章:
搞疯爬虫程序员的8个难点!!
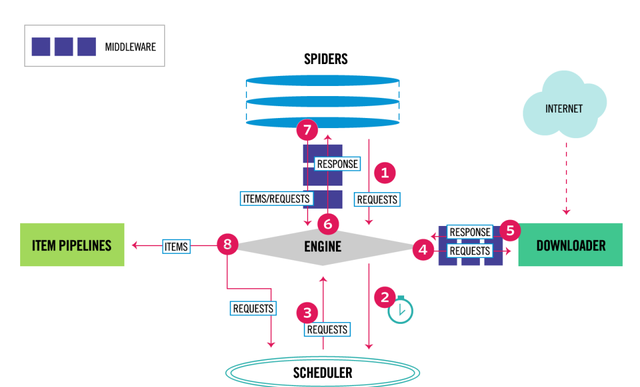
工程化框架 – scapy
在Python的世界里,工程化最常用的就是Scrapy框架,它使用组件化的方式分解了爬虫所需要处理的事情,让你可以集中在最关键的地方,剩下的管理工作交给框架来完成。
声明:本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。E-MAIL:dandanxi6@qq.com