
0.问题及排查思路
0.1 线上故障
线上服务器服务进程假死,进程还存在,但是日志已经不打印了,访问失败超时不响应。
0.2 排查思路
0.2.1 使用 jps -l 查看java进程的进程号 假设进程号为9999
[root@izbp1bym5hklu4zctqz logs]$ jps -l24611 com.alibaba.dubbo.container.Main11015 sun.tools.jps.Jps15113 com.alibaba.dubbo.container.Main9999 com.alibaba.dubbo.container.Main0.2.2 使用jmap -heap 9999 查看jvm内存使用情况 发现老年代使用已经满了
Heap Configuration: MinHeapFreeRatio = 40 MaxHeapFreeRatio = 70 MaxHeapSize = 1073741824 (1024.0MB) NewSize = 134217728 (128.0MB) MaxNewSize = 134217728 (128.0MB) OldSize = 939524096 (896.0MB) NewRatio = 2 SurvivorRatio = 8 MetaspaceSize = 21807104 (20.796875MB) CompressedClassSpaceSize = 1073741824 (1024.0MB) MaxMetaspaceSize = 17592186044415 MB G1HeapRegiOnSize= 0 (0.0MB)Heap Usage:New Generation (Eden + 1 Survivor Space): capacity = 120848384 (115.25MB) used = 76972312 (73.4065170288086MB) free = 43876072 (41.843482971191406MB) 63.693290263608326% usedEden Space: capacity = 107479040 (102.5MB) used = 76972312 (73.4065170288086MB) free = 30506728 (29.093482971191406MB) 71.6161141744474% usedFrom Space: capacity = 13369344 (12.75MB) used = 0 (0.0MB) free = 13369344 (12.75MB) 0.0% usedTo Space: capacity = 13369344 (12.75MB) used = 0 (0.0MB) free = 13369344 (12.75MB) 0.0% usedconcurrent mark-sweep generation: capacity = 939524096 (896.0MB) used = 939524048 (895.9999542236328MB) free = 48 (4.57763671875E-5MB) 99.99999489103045% used0.2.3 在服务启动时 开启gc日志 可以查看gc日志 参数为 -Xloggc:./gclogs -XX:+PrintGC +PrintGCDetails
0.2.4 调试参数时 可以使用 jinfo -flags pid 查看目前参数 jinfo -flag +PrintGC 9999 或者使用jinfo 进程号 查看进程的配置参数。或者修改参数(部分可以修改)
1.垃圾回收器介绍
1.1 新生代使用ParNew收集器
ParNew是一个Serial收集器的多线程版本,会使用多个CPU和线程完成垃圾收集工作(默认使用的线程数和CPU数相同,可以使用-XX:ParallelGCThreads参数限制)。该收集器采用复制算法回收内存,期间会停止其他工作线程,即Stop The World。
1.2 老年代使用CMS收集器
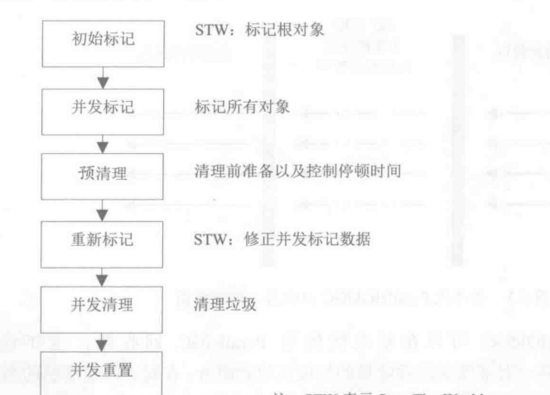
CMS收集周期
初始标记(CMS-initial-mark) -> 并发标记(CMS-concurrent-mark)->重新标记(CMS-remark) -> 并发清除(CMS-concurrent-sweep) -> 并发重设状态等待下次CMS的触发(CMS-concurrent-reset)。
- initial-mark 初始标记(CMS的第一个STW阶段),标记GC Root直接引用的对象,GC Root直接引用的对象不多,所以很快。
- concurrent-mark 并发标记阶段,由第一阶段标记过的对象出发,所有可达的对象都在本阶段标记。
- concurrent-preclean 并发预清理阶段,也是一个并发执行的阶段。在本阶段,会查找前一阶段执行过程中,从新生代晋升或新分配或被更新的对象。通过并发地重新扫描这些对象,预清理阶段可以减少下一个stop-the-world 重新标记阶段的工作量。
- concurrent-abortable-preclean 并发可中止的预清理阶段。这个阶段其实跟上一个阶段做的东西一样,也是为了减少下一个STW重新标记阶段的工作量。增加这一阶段是为了让我们可以控制这个阶段的结束时机,比如扫描多长时间(默认5秒)或者Eden区使用占比达到期望比例(默认50%)就结束本阶段。
- remark 重标记阶段(CMS的第二个STW阶段),暂停所有用户线程,从GC Root开始重新扫描整堆,标记存活的对象。需要注意的是,虽然CMS只回收老年代的垃圾对象,但是这个阶段依然需要扫描新生代,因为很多GC Root都在新生代,而这些GC Root指向的对象又在老年代,这称为“跨代引用”。
- concurrent-sweep ,并发清理

2.内存模型及参数含义
2.1 垃圾回收图示

2.2 调优参数与含义
-XX:+PrintGC //打印GC的简要信息 [GC (Allocation Failure) 62617K->1177K(236032K), 0.0004510 secs]-XX:+PrintGCApplicationStoppedTime //打印了在safepoints内花费的时间-XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1 //记录Stop The World发生的原因、线程情况、STW各个阶段的停顿时间-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小-XX:MaxTenuringThreshold=15 //设置对象晋升到老年代的阈值 -XX:PermSize -XX:MaxPermSize //jdk1.7 设置初始化方法区和最大方法区大小-XX:MetaspaceSize和-XX:MaxMetaspaceSize // jdk1.8设置元空间初始大小以及最大可分配大小 初始大小默认21-Xms64m //最小堆内存 64m-Xmx128m //最大堆内存 128m-Xmn128m //设置年轻代大小 推荐配置为整个堆的3/8-XX:NewSize=30m 年轻代初始化大小为30m 与-Xmn相同 写在最后的生效-XX:MaxNewSize=40m 年轻代最大大小为40m-Xss=256k 线程栈大小 越小产生越多线程-XX:+PrintHeapAtGC 当发生 GC 时打印内存布局-XX:+HeapDumpOnOutOfMemoryError 发送内存溢出时 dump 内存-XX:NewRatio=2 //设置老年代/年轻代的比例-XX:-UseAdaptiveSizePolicy //survivor和eden区大小自动变化,默认开启的,关掉就是严格的1:8-XX:+DisableExplicitGC //代码中手动调用System.gc()不会生效-XX:+CMSParallelRemarkEnabled //并行运行最终标记阶段,加快最终标记的速度-XX:LargePageSizeInBytes //大内存分页大小-XX:+UseFastAccessorMethods get,set //方法转成本地代码-XX:TargetSurvivorRatio //如果Survivor空间的占用超过该设定值,对象在未达到他们的最大年龄之前就会被提升至老年代 默认50-XX:PretenureSizeThreshold //超过这个值的时候,对象直接在old区分配内存。默认值是0,意思是不管多大都是先在eden中分配内存。-XX:+UseCMSCompactAtFullCollection //每次触发CMS Full GC的时候都整理一次碎片-XX:+UseCMSInitiatingOccupancyOnly //只根据老年代使用比例来决定是否进行CMS-XX:CMSInitiatingOccupancyFraction //设置触发CMS老年代回收的内存使用率占比3.GC日志分析与调优思路
3.1 GC日志
2021-12-18T11:29:01.847+0800: 4.178: [GC (CMS Final Remark) [YG occupancy: 64244 K (118016 K)]2021-12-18T11:29:01.847+0800: 4.178: [Rescan (parallel) , 0.0092320 secs]2021-12-18T11:29:01.857+0800: 4.187: [weak refs processing, 0.0000406 secs]2021-12-18T11:29:01.857+0800: 4.187: [class unloading, 0.0065586 secs]2021-12-18T11:29:01.863+0800: 4.194: [scrub symbol table, 0.0049186 secs]2021-12-18T11:29:01.868+0800: 4.198: [scrub string table, 0.0008765 secs][1 CMS-remark: 19724K(917504K)] 83969K(1035520K), 0.0220519 secs] [Times: user=0.09 sys=0.00, real=0.03 secs] 2022-02-24T16:47:25.942+0800: 7265.295: [GC (Allocation Failure) 2022-02-24T16:47:25.942+0800: 7265.295: [ParNew: 1269715K->14304K(1415616K), 0.0115139 secs] 1484696K->230073K(1939904K), 0.0116049 secs] [Times: user=0.07 sys=0.00, real=0.01 secs]年轻代 1415616k的时候 触发年轻代回收 总大小1415616m 115m->12m堆区 总大小1035520k 1011.25m 125m->27m[Times: user=0.06 sys=0.00, real=0.01 secs] 分别表示用户态耗时,内核态耗时和总耗时3.2 调优思路
当发生 Minor GC 时,Eden 区和 from 指向的 Survivor 区中的存活对象会被复制到 to 指向的 Survivor 区中,然后交换 from 和 to 指针,以保证下一次 Minor GC 时,to 指向的 Survivor 区还是空的。当然,你也可以通过参数 -XX:SurvivorRatio 来固定这个比例。但是需要注意的是,其中一个 Survivor 区会一直为空,因此比例越低浪费的堆空间将越高。Java 虚拟机会记录 Survivor 区中的对象一共被来回复制了几次。如果一个对象被复制的次数为 15(对应虚拟机参数 -XX:+MaxTenuringThreshold),那么该对象将被晋升(promote)至老年代。另外,如果单个 Survivor 区已经被占用了 50%(对应虚拟机参数 -XX:TargetSurvivorRatio),那么较高复制次数的对象也会被晋升至老年代.Minor GC 的另外一个好处是不用对整个堆进行垃圾回收。
但是,它却有一个问题,那就是老年代的对象可能引用新生代的对象。也就是说,在标记存活对象的时候,我们需要扫描老年代中的对象。如果该对象拥有对新生代对象的引用,那么这个引用也会被作为 GC Roots。这样一来,岂不是又做了一次全堆扫描呢?卡表HotSpot 给出的解决方案是一项叫做卡表(Card Table)的技术。该技术将整个堆划分为一个个大小为 512 字节的卡,并且维护一个卡表,用来存储每张卡的一个标识位。这个标识位代表对应的卡是否可能存有指向新生代对象的引用。如果可能存在,那么我们就认为这张卡是脏的。在进行 Minor GC 的时候,我们便可以不用扫描整个老年代,而是在卡表中寻找脏卡,并将脏卡中的对象加入到 Minor GC 的 GC Roots 里。当完成所有脏卡的扫描之后,Java 虚拟机便会将所有脏卡的标识位清零。
对应一个 64 位的服务端 JVM 来说,其默认的 -XX:MetaspaceSize 值为 21MB ,这就是初始的高水位线,一旦元空间的大小触及这个高水位线,就会触发 Full GC 并会卸载没有用的类,然后高水位线的值将会被重置。如果初始化的高水位线设置过低,会频繁的触发 Full GC ,高水位线会被多次调整。所以为了避免频繁 GC 以及调整高水位线,建议将 -XX:MetaspaceSize 设置为较高的值,而 -XX:MaxMetaspaceSize 不进行设置。
触发Full GC条件
1.显式调用System.gc方法(建议JVM触发)
2.空间担保分配是指在发生Minor GC之前,虚拟机会检查老年代最大可用的连续空间是否大于新生代所有对象的总空间
3.老年代空间不足,主要由以下情况引起
- 大对象直接进入老年代引起老年代空间不足,-XX:PretenureSizeThreshold参数,超过这个值的时候,对象直接在old区分配内存。默认值是0,意思是不管多大都是先在eden中分配内存。
- Minor GC时,经历过多次Minor GC仍存在的对象进入老年代。上面提过,由-XX:MaxTenuringThreashold参数定义
- Minor GC时,动态对象年龄判定机制会将对象提前转移老年代。年龄从小到大进行累加,当加入某个年龄段后,累加和超过survivor区域 -XX:TargetSurvivorRatio 如果Survivor空间的占用超过该设定值,对象在未达到他们的最大年龄之前就会被提升至老年代,从这个年龄段往上的年龄的对象进入老年代
- Minor GC时,Eden和From Space区向To Space区复制时,大于To Space区可用内存,会直接把对象转移到老年代。
3.3 最终调优方式
3.3.1 jvm调优
#之前的参数-server -Xmx1g -Xms1g -Xmn128m -XX:PermSize=64m -Xss256k #优化后的参数-server -Xmx4g -Xms2g -Xmn1536m -XX:PermSize=128m -Xss256k声明:本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。E-MAIL:dandanxi6@qq.com