
本文将手把手地教大家从零开始用Java写一个简单地爬虫!

目标
爬取全景网图片,并下载到本地
收获
通过本文,你将复习到:
- IDEA创建工程
- IDEA导入jar包
- 爬虫的基本原理
- Jsoup的基本使用
- File的基本使用
- FileOutputStream的基本使用
- ArrayList的基本使用
- foreach的基本使用
说明
爬虫所用的HTM解析器为Jsoup。Jsoup可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
Jsoup相关API整理见文末附录一。
开始
一、前端分析
1、使用Chrome或其他浏览器,打开全景网,按F12进入调试模式,分析网页结构。(这里选的是“创意”=>“优山美地”)
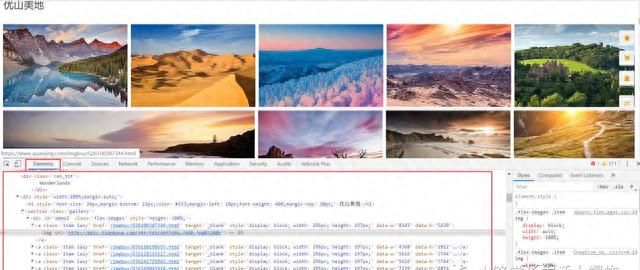
2、找规律,看图片对应的结构是什么。可以发现,每个图片的结构都如下图红框所示。
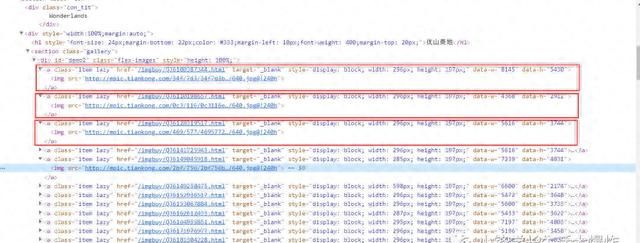
3、找到结构后再找图片链接。进一步分析后发现,图片链接可以是下图红框部分。

4、复制到浏览器打开看看验证下。(好吧,访问这个URL直接给我下载了…)

5、前端部分分析完毕,接下来就可以用Java编码了!
二、爬取思路
通过Java向全景网发送GET请求,以获取HTML文件。Jsoup解析后寻找class=item lazy的a标签,他的child节点(即<img>)就是我们要找的目标节点了,搜索到的应当是一个ArrayList。然后遍历集合,从中搜寻图片的URL,并下载到本地保存。(更深一步,可以下载完一页后,继续下载后一页,直至全部下完。本文直讲下载第一页。提示一下,链接后面的topic/1其实就是当前页数)
三、Java编码
1、先下载Jsoup jar包,并导入到IDEA工程中。
2、新建Java工程。
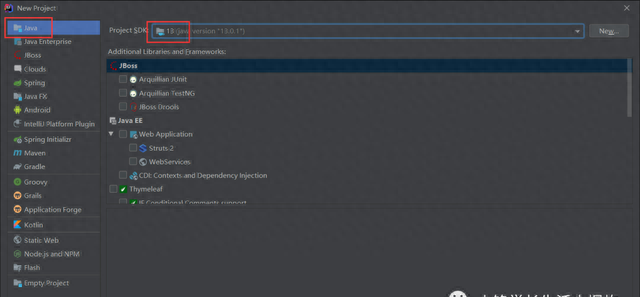
3、简单测试下get请求,若请求成功,则进入下一步;若报错,检查URL是否带了中文。
注意:链接没给,否则文章审核不过,注意自己添加!!!
package com.sxf;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;public class Main { public static void main(String[] args) { try { Document doc = Jsoup.connect("").get(); //这里加链接 System.out.println(doc); }catch (Exception e){ e.printStackTrace(); } }}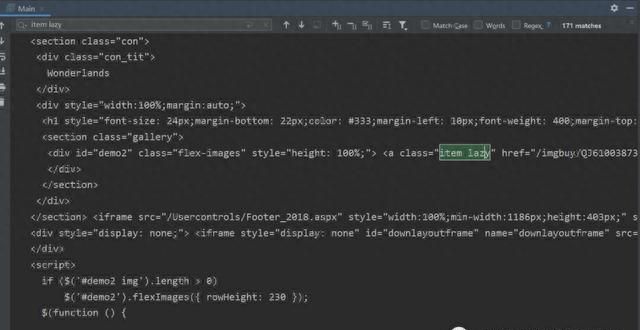
4、寻找class为item lazy的元素,找到他的child节点,返回ArrayList。并将图片的URL单独提取出来。
注意:链接没给,否则文章审核不过,注意自己添加!!!
注意:链接没给,否则文章审核不过,注意自己添加!!!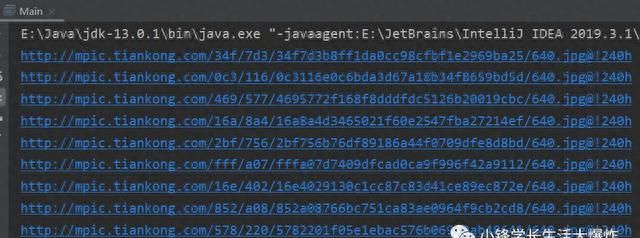
5、我们先尝试用Jsoup下载一张图片试试效果。
注意:链接没给,否则文章审核不过,注意自己添加!!!
// 获取responseConnection.Response imgRes = Jsoup.connect(URLS.get(0)).ignoreContentType(true).execute();FileOutputStream out = (new FileOutputStream(new java.io.File("demo.jpg")));// imgRes.body() 就是图片数据out.write(imgRes.bodyAsBytes());out.close();可以看到在当前工程路径下,生成了demo.jpg图片,并且显示正常!
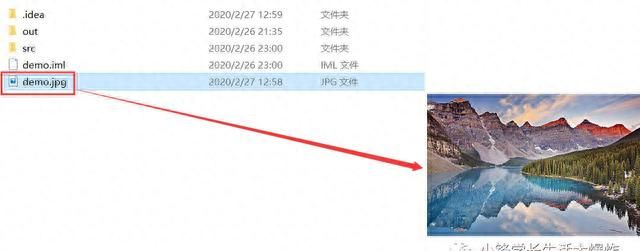
6、接下来,我们要创建一个文件夹,用来专门存放图片。
File相关API整理见文末附录二。
//当前路径下创建Pics文件夹File file = new File("Pics");file.mkdir();System.out.println(file.getAbsolutePath());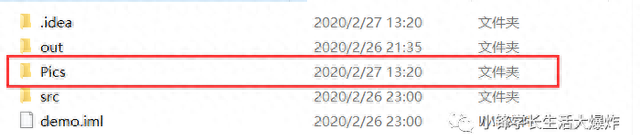
7、接下来开始遍历图片并下载。由于图片较多,为了简单起见,我们保存图片时候的名称,就从1开始依次增吧。
// 遍历图片并下载int cnt = 1;for (String str : URLS) { System.out.println(">> 正在下载:"+str); // 获取response Connection.Response imgRes = Jsoup.connect(str).ignoreContentType(true).execute(); FileOutputStream out = (new FileOutputStream(new java.io.File(file, cnt+".jpg"))); // imgRes.body() 就是图片数据 out.write(imgRes.bodyAsBytes()); out.close(); cnt ++;}运行结果
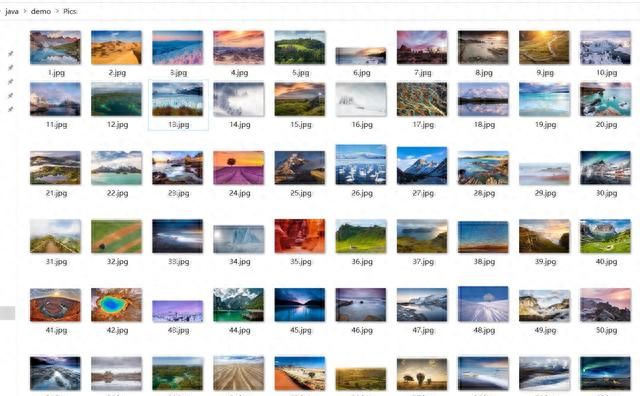
到此编码部分也结束了,完整代码见文末附件三!
附录一
Jsoup(HTML解析器)
继承关系:Document继承Element继承Node。TextNode继承Node。->java.lang.Object ->org.jsoup.nodes.Node ->org.jsoup.nodes.Element ->org.jsoup.nodes.Documenthtml文档:Document元素操作:Element节点操作:Node官方API:***/apidocs/org/jsoup/nodes/Document.html 一、解析HTML并取其内容 Document doc = Jsoup.parse(html);二、解析一个body片断 Document doc = Jsoup.parseBodyFragment(html); Element body = doc.body();三、从一个URL加载一个Document Document doc = Jsoup.connect("***") .data("query", "Java") .userAgent("Mozilla") .COOKIE("auth", "token") .timeout(3000) .post(); String title = doc.title();四、从一个文件加载一个文档 File input = new File("/tmp/input.html"); // baseUri 参数用于解决文件中URLs是相对路径的问题。如果不需要可以传入一个空的字符串 Document doc = Jsoup.parse(input, "UTF-8", "***/"); 五、使用DOM方法来遍历一个文档 1、查找元素 getElementById(String id) getElementsByTag(String tag) getElementsByClass(String className) getElementsByAttribute(String key) // 和相关方法 // 元素同级 siblingElements() firstElementSibling() lastElementSibling() nextElementSibling() previousElementSibling() // 关系 parent() children() child(int index) 2、元素数据 // 获取属性attr(String key, String value)设置属性 attr(String key) // 获取所有属性 attributes() id() className() classNames() // 获取文本内容text(String value) 设置文本内容 text() // 获取元素内HTMLhtml(String value)设置元素内的HTML内容 html() // 获取元素外HTML内容 outerHtml() // 获取数据内容(例如:script和style标签) data() tag() tagName() 3、操作HTML和文本 append(String html) prepend(String html) appendText(String text) prependText(String text) appendElement(String tagName) prependElement(String tagName) html(String value) 六、使用选择器语法来查找元素(类似于CSS或jquery的选择器语法) //带有href属性的a元素 Elements links = doc.select("a[href]"); //扩展名为.png的图片 Elements pngs = doc.select("img[src$=.png]"); //class等于masthead的div标签 Element masthead = doc.select("div.masthead").first(); //在h3元素之后的a元素 Elements resultLinks = doc.select("h3.r > a"); 七、从元素抽取属性、文本和HTML 1、要取得一个属性的值,可以使用Node.attr(String key) 方法 2、对于一个元素中的文本,可以使用Element.text()方法 3、对于要取得元素或属性中的HTML内容,可以使用Element.html(), 或 Node.outerHtml()方法 4、其他: Element.id() Element.tagName() Element.className() Element.hasClass(String className)附录二
File类
*java.io.File类用于表示文件或目录。*创建File对象:// 文件/文件夹路径对象File file = new File("E:/...");// 父目录绝对路径 + 子目录名称File file = new File("..." ,"");// 父目录File对象 + 子目录名称 File file = new File("...","...");file.exists():判断文件/文件夹是否存在file.delete():删除文件/文件夹file.isDirectory():判读是否为目录file.isFile():判读是否为文件夹file.mkdir():创建文件夹(仅限一级目录)file.mkdirs():创建多及目录文件夹(包括但不限一级目录)file.createNewFile():创建文件file.getAbsolutePath():得到文件/文件夹的绝对路径file.getName():得到文件/文件夹的名字file.String():同样是得到文件/文件夹的绝对路径等于file.getAbsolutePath()file.getParent():得到父目录的绝对路径附录三
完整代码
package com.sxf;import org.jsoup.Connection;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import java.io.File;import java.io.FileOutputStream;import java.util.ArrayList;public class Main { public static void main(String[] args) { try { Document doc = Jsoup.connect("***/creative/topic/1").get(); // 寻找class为item lazy的元素,返回ArrayList。 Elements items = doc.getElementsByClass("item lazy"); ArrayList<String> URLS = new ArrayList<>(); // 将图片的URL单独提取出来。 for (Element i : items) { URLS.add(i.child(0).attr("src")); } // 当前路径下创建Pics文件夹 File file = new File("Pics"); file.mkdir(); String rootPath = file.getAbsolutePath(); System.out.println(">> 当前路径:"+rootPath); // 遍历图片并下载 int cnt = 1; for (String str : URLS) { System.out.println(">> 正在下载:"+str); // 获取response Connection.Response imgRes = Jsoup.connect(str).ignoreContentType(true).execute(); FileOutputStream out = (new FileOutputStream(new java.io.File(file, cnt+".jpg"))); // imgRes.body() 就是图片数据 out.write(imgRes.bodyAsBytes()); out.close(); cnt ++; } }catch (Exception e){ e.printStackTrace(); } }}声明:本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。E-MAIL:dandanxi6@qq.com