
工作中,我们可能会碰到一些需求,需要比较不同图像的相似度,或者从大量图片中快速找到相似图片,这就需要借助相应的图像相似度算法来帮助我们实现。另外,机器学习和人工智能的大部分应用场景,都需要借助图像相似度算法,这也算是学习AI的重要一步。所以,在这里,我们一起探究主流的图像相似度算法,并尝试用OpenCV和Python来做简单实现。最后,根据不同相似度算法的优劣,总结出其对应的适用场景。
在比较两个图片的时候,我们总会有一些不同的需求,有时候我们希望能精确的比较两个图片是否完全相等,有时候,我们希望仅仅比较图像的相似度。
想要研究这个是因为最近我们碰到一个问题,我们想要检测两个图片是否相等,当这两个图片完全相同的时候,我们希望可以直接了当的返回一个True,当这两个图片有一丢丢的差距的时候,我们也希望可以返回True。但是如果严格用差值法对比图片,第二个需求就不满足,所以需要通过研究图像的相似性来解决目前的问题。
暴力判断
比较两个图片是否相等有很多方法,最直观的,也最容易想到的算法就是遍历两个图片的每一个像素,最终求差来得到两个图片是否相等。
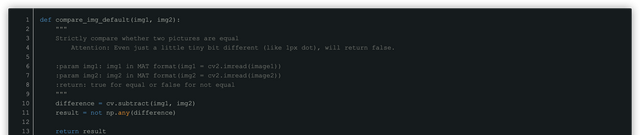

这种方式的优点是速度很快,比较精度特别高,但是如果两个图片稍微有一点不同,哪怕只是一个像素的差距,都会返回False。
因此,该算法的适用性并不广泛,除非你的需求就是要判断两张图片严格相等,但是多数情况下,我们需求都是比较两张图片是否相似。所以,接下来,我们来看看市面上主流的图像相似度的判别算法。
图像相似的判别算法
图像相似也有很多判别法,我没有去尝试每一种方法,但是基本上所有的方法都了解了一遍,在这里总结一下主流的算法,同时也是巩固一下。
直方图比较法
直方图比较法是一个比较基础,也比较简单快捷的一种办法,目前我就是使用这个方法作为项目的主力相似性判别法。
直方图比较的原理是,将所要比较的两幅图片的直方图数据,然后再将直方图数据归一化之后方便比较,最终得到一个相似指数,通过设定相似指数的边界,我们可以得到是否是同一张图片。
下面,用OpenCV和Python实现如下:
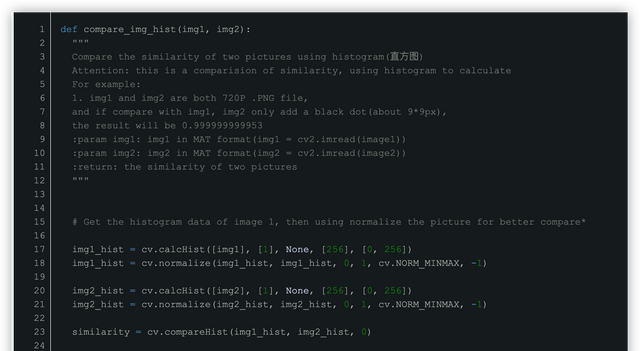
直方图算法运行速度很快,也是比较图片相似度算法中很受欢迎的算法,如果你的项目中,需要比较有着极高相似度的图片,而且你需要将这种具有极高相似度的图片归为同一个图片,那么就选用直方图算法吧!
哈希算法
感知哈希算法(pHash,全拼:Perceptual hash algorithm)是哈希算法的一种,哈希算法还包括平均值哈希算法(aHash),差异值哈希算法(dHash),经过对比之后,最终决定采用pHash算法来作为辅助相似性判别法。
pHash简单来说,是通过感知哈希算法对每张图片生成一个“指纹”字符串,然后通过比较“指纹”字符串的距离(通常采用汉明距离,Hamming distance,两个等长字符串之间的汉明距离,是两个字符串对应位置的不同字符的个数),这个距离越小,代表两个图片越相似,一般的,我们有下面规则:
Hamming distance = 0 -> particular like
Hamming distance < 5 -> very like
hamming distance > 10 -> different picture
关于aHash, pHash, dHash的区别,我总结如下:
· aHash:平均值哈希。转灰度压缩之后计算均值,最终通过像素比较得出哈希值,速度很快,但敏感度很高,稍有变化就会极大影响判定结果,精准度较差。因此比较适用于缩略图比较,最常用的就是以图搜图。
· pHash:感知哈希。在均值哈希基础上加入DCT(离散余弦变化,下面也会涉及,这里不展开),两次DCT就可以很好的将图像按照频度分开,取左上角高能低频信息做均值哈希,因此,精确度很高,但是速度方面较差一些。
· Opencv实测速度比平均哈希慢大概200ms~700ms左右(我自己的开发机,不同机器,不同版本可能结果也会不同)。相比较aHash,pHash更加适合用于缩略图比较,也非常适合比较两个近似图片是否相等。
· 比如你所要比较的两张图片就只有一个button有变化,其余的都没有变化,采用严格的aHash很有可能就得到错误的结果,这种情况就可以放心大胆的采用pHash算法进行比较。实际上,这个场景就是我们项目中实际碰到的,最终也是通过pHash来解决的。
· dHash:差异值哈希。转灰度压缩之后,比较相邻像素之间差异。
· 假设有10×10的图像,每行10个像素,就会产生9个差异值,一共10行,就一共有9×10=90个差异值。最终生成哈希值即指纹。
· 速度上来说,介于aHash和pHash之间,精准度同样也介于aHash和pHash之间。所以前两种哈希的适用场景,dHash也完全适用,如果你想要一个精准度较高而且速度比较快的算法,那就选择dHash吧!
- Reduce size. The fastest way to remove high frequencies and detail is to shrink the image. In this case, shrink it to 8×8 so that there are 64 total pixels. Don't bother keeping the aspect ratio, just crush it down to fit an 8×8 square. This way, the hash will match any variation of the image, regardless of scale or aspect ratio.
- Reduce color. The tiny 8×8 picture is converted to a grayscale. This changes the hash from 64 pixels (64 red, 64 green, and 64 blue) to 64 total colors.
- Average the colors. Compute the mean value of the 64 colors.
- Compute the bits. This is the fun part. Each bit is simply set based on whether the color value is above or below the mean.
- Construct the hash. Set the 64 bits into a 64-bit integer. The order does not matter, just as long as you are consistent. (I set the bits from left to right, top to bottom using big-endian.)
The resulting hash won't change if the image is scaled or the aspect ratio changes. Increasing or decreasing the brightness or contrast, or even altering the colors won't dramatically change the hash value. And best of all: this is FAST!
这里均值哈希的实现:
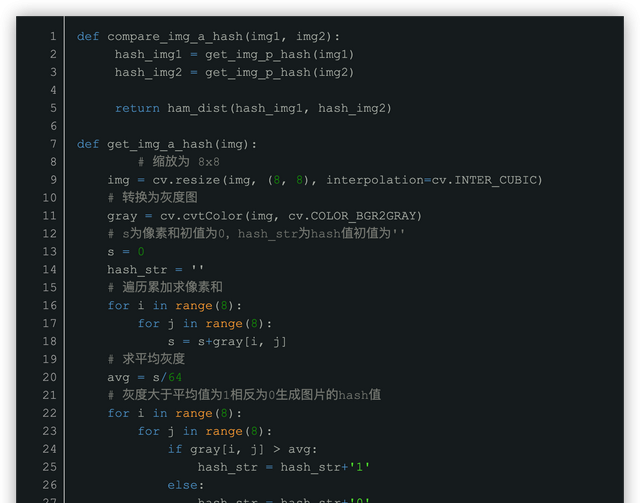
pHash在均值哈希算法的基础上,加入了离散余弦变换(DCT,Discrete cosine transform),数学不精通的同学可能这里就有点着急了,简单解释一下离散余弦变化,其作用是为了减少图像的冗余和相关性,是一种图像压缩算法,将图像从像素域变换到频率域。详细请前往(离散余弦变换)
我们用步骤来描述如何将DCT加入到pHash中:
1. 缩小尺寸:pHash以小图片开始,但图片大于8×8,32×32是最好的(我这里选用的是32×32的,计算量完全OK)。这样做的目的是简化了DCT的计算,而不是减小频率。
2. 简化色彩(灰度化):将图片转化成灰度图像,一个只由0~255整数来表示的灰度图,由此进一步简化计算量。
3. 计算DCT:计算图片的DCT变换,得到32×32的DCT系数矩阵。
4. 缩小DCT:虽然DCT的结果是32×32大小的矩阵,但我们只要保留左上角的8×8的矩阵,这部分呈现了图片中的最低频率。
5. 计算平均值:如同均值哈希一样,计算DCT的均值。
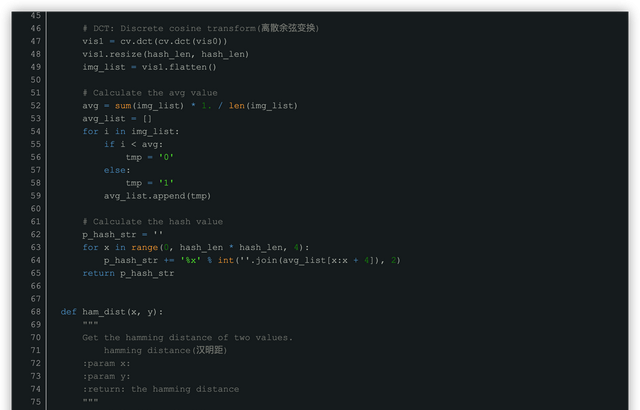
6. 计算hash值:这是最主要的一步,根据8×8的DCT矩阵,设置0或1的64位的hash值,大于等于DCT均值的设为”1”,小于DCT均值的设为“0”。组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。
基于以上步骤,我们实现了一个简单的pHash算法,同样,使用OpenCV和Python来实现:
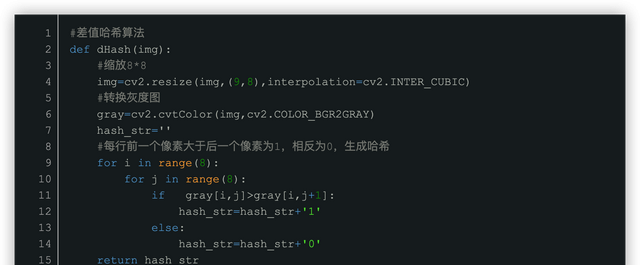
差值哈希算法前期和后期基本相同,只有中间比较hash有变化。
步骤
1. 缩放: 图片缩放为8*9,保留结构,出去细节。
2. 灰度化:转换为256阶灰度图。
3. 求平均值:计算灰度图所有像素的平均值。
4. 比较:像素值大于后一个像素值记作1,相反记作0。本行不与下一行对比,每行9个像素,八个差值,有8行,总共64位
5. 生成hash:将上述步骤生成的1和0按顺序组合起来既是图片的指纹(hash)。顺序不固定。但是比较时候必须是相同的顺序。
其他相似性比较算法
除了上述直方图和哈希算法之外,还有其他的一些算法,我列举如下:
1. 内容特征法
内容特征法和直方图比较法比较相似,只不过是从比较图像内容入手的,通常的做法是压缩灰度化之后来比较前景色和背景色的反差。通过设定一个值,来区分前景色和背景色,我们前面简单说过,灰度化就是用0~255来表示所有的像素,我们设定一个值,比如说130,大于130的,我们称之为背景色,反之,称之为前景色。最终,我们通过一个公式(被称为大津法,Otsu's method,维基百科):
我们记:
前景色占比 F=前景色像素数/总体像素数
背景色占比 B=背景色像素数/总体像素数
前景色平均值和方差 F1,F2
背景色平均值和方差 B1,B2,则:
类内差异 = F(F2^2) + B(B2^2)
类间差异 = FB(F1-B1)^2
使得前景色和背景色的“类内差异最小”,得到一个阈值,将阈值和每一个像素比较之后,就得到了该图片的0-1特征矩阵,通过比较两个不同图片的特征矩阵即可得到图片之间的相似度。
该算法也除了用于图片相似度之外,也常用于找不同,找不同的精确度很高,速度相较于直方图,差距不明显,如果你有找不同的需求,可以使用这个算法来做,但是如果你有模糊匹配的需求,该算法就非常不合适了。该算法也可用于媒体处理,如视频跟踪,运动检测等。
2.关键点匹配
或者叫特征点匹配,使用特征描述子来做角点检测,特征描述子通常是一个向量,两个向量之间的距离就可以用来比较其相似度。
3. SSIM(structural similarity,结构相似性)
这里摘抄一段维基百科关于PSNR的定义:
The structural similarity** (SSIM) index is a method for predicting the perceived quality of digital television and cinematic pictures, as well as other kinds of digital images and videos. The basic model was developed in the Laboratory for Image and Video Engineering(LIVE) at The University of Texas at Austin and further developed jointly with the Laboratory for Computational Vision (LCV) at New York University. Further variants of the model have been developed in the Image and Visual Computing Laboratory at University of Waterloo and have been commercially marketed.
SSIM作为一种全参考的图像相似度算法,从亮度、对比度和结构三方面来比较图像相似度,大名鼎鼎,使用广泛。初期我也将其运用到项目中,但是实际运行效果发现,耗时有点长,而且结果还没有直方图来的简单直接,给人一种杀鸡焉用牛刀的感觉,所以最终还是放弃了。
结语
文中列出的是主流的最常使用的一些算法,还有一些其他算法,没有列出,是因为在了解过程中,根据需求最终决定不去尝试,不然试错成本太高,有一些明显不合适的算法就简单了解就可以了。
最后,不是最好的就是最合适的,这里建议以项目驱动,满足项目需求即可。
参考
· 使用哈希算法实现图像相似度比较
· 图像相似度算法探究及其适用场景分析
声明:本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。E-MAIL:dandanxi6@qq.com