
声音秒变志玲姐姐,秒变「矮大紧」,秒变萝莉、正太,现在通通不是问题!
近日,搜狗公司 CEO 王小川在一场大会上展示了搜狗变声功能,可以让你的声音秒变志玲姐姐,下一秒变马云,下一秒再变高晓松。
这一语音变声技术可以实现把任何人的声音转化成特定声音,即「Anyone to One」. 这是表征学习在变声应用方面的一个突破,搜狗将这项技术落地搜狗输入法中,在行业率先实现落地商用。
在搜狗输入法中,搜狗目前提供了明星、卡通人物、游戏 IP、方言等几个类别供 19 种特定声音,你可以将自己的声音自由变换成喜欢的声音,目前在微信、QQ、陌陌等主要社交场景均可使用。
更为重要的是,当搜狗将自身的语音变声技术、AI 合成主播技术等与行业结合,尤其尤其是与媒体、教育、内容制作、旅游等场景结合,将会带来更大的价值想象空间。
一、搜狗语音变声实测:逼真度高、自由度高
在搜狗输入法中,通过「变声」功能,我们的声音可以转化为明星、动漫人物、游戏人物等各种炫酷的嗓音。目前,搜狗输入法的「变声」功能可转化为 19 种不同音色的语音,可以在微信、QQ 等聊天时使用,更像一种「语音表情包」,为社交增添新的玩法。
我们先看看语音变声到底是什么样的:
可以看出,搜狗语音变声是一种将任意说话人音色实时高逼真度变换到指定说话人音色的技术,即把我们的说话内容和风格完整地迁移到特定对象的语音上。这种变声要比单纯的变音难很多,最重要的是模型需要通过深度学习从语音抽取特定的嵌入向量,这些嵌入向量表示了说话的内容、风格、情感、音色等信息,并用目标音色代替原始音色实现变声。
它主要有如下三大特点:
高还原度的变声:变声结果和目标说话人的真实嗓音非常像;
自由度极高的变声:使用者的语音没有任何限制,选定目标嗓音后,不同使用者变声后的嗓音能保持一致。也就是说这是一种 Any-to-One 的方式,任意人变声到一人的能力;
风格迁移的变声:我们的说话内容、风格(语速、停顿、情感等)都能保留下来,只是音色变换到选定的目标嗓音。
语音变声是搜狗的创新,这是全新的发展领域比语音合成更具有广泛的使用场景。同时,搜狗则在语音表征学习、迁移学习技术的突破基础上,再进一步将其部署到产品中,率先在行业实现落地。
而 Any-to-One 的方式意味着,模型不对说话人做约束,就可以实现变声到制定目标音色的迁移效果。模型训练只需要几十分钟的声音语料即可学习到目标语音的特点,所以如果你想定制一个变声语音,成本并不会很大。
二、受益表征学习突破 详解搜狗变声模型
搜狗语音交互中心高级总监陈伟表示,搜狗语音变声技术的突破,主要是在表征学习的研究上取得的,基于大量的语音数据,从中学习到有效表达说话人不同维度信息和属性的表征。
针对变声的任务需要学习到三类表征:
说话人无关的内容表征:基于大量说话人语音数据,从中学习提取说话人无关表征的模型;
目标说话人声纹表征,它表示不同人的「嗓音」差别。不同的声纹特征向量,对应着不同的目标音色;
说话风格的表征,模型还应该学习到各种说话风格韵律相关的特征,例如语速的快慢和情感的起伏等。
搜狗构建的模型,主要会从说话人语音的音色、内容和韵律 (讲话节奏、情感语气等信息) 三个维度描述相关特征。并将学习到的说话人音色特征替换成目标说话人,最后基于搜狗语音到语音的新技术生成变声音频。
当这三类特征都能学习出来时,通过模型的学习进行解码生成对应目标音色的语音,从而实现将源说话人的内容和风格迁移到目标说话人的音色。
变声的架构
那么这些特征都是怎样联合,并完成变声的呢?陈伟解释了变声功能的整体架构与过程,它是一个端到端的高效模型。对应上面所述的三类特征,编码部分可以分为 A、B、C 三个子模块。每一个模块负责一类特征,最后结合三种特征而解码为目标语音、。如下为变声功能的整体架构:
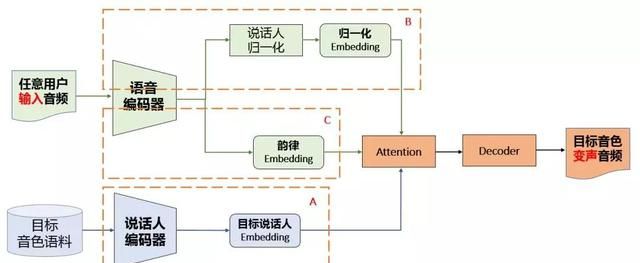

其中 A、B、C 组成了表征学习部分,后面的注意力机制和解码器组成了语音变声模块。这里可能令人疑惑的是,为什么说 B 和 C 两个嵌入向量能学习到内容与韵律,注意力机制又是怎样结合三大特征?
嵌入向量是什么?
A 的嵌入向量能学习到声纹信息并不难理解。如果嵌入向量能区分不同的说话人,那么就表示它学习到了不同人的音色或嗓音,A 也就完成了对音色语料的声纹特征编码。
但问题是,为什么 B 和 C 两个模块能从输入音频中学习到内容与韵律?
陈伟表示,这两个向量都要加一些约束才能学习到不同的特征。现在很多模型学习到的表征都是采用无监督的方式,例如自编码器、基于流的方法,学习到的表征并不能确定具体表示什么。只有人工再去判断,我们才能知道它可能和语音、图像的哪些属性相关。
但是在 B 和 C 两个模块中,模型的目的非常明确,它希望学习到与内容和风格相关的特征。在这个过程中需要其它约束与监督信息,使模型朝着具体的方向学习。具体而言,如果 B 希望学习到内容相关的特征,那么可能就需要语音内容进行约束。只有 B 的嵌入向量能重构出文本内容,这才表示它确实学到了。
注意在 B 中会有一个说话人归一化的模块,主要用来去除音色信息。
注意的是什么?
对于语音变声中,若得到各种嵌入向量,并通过注意力机制加权成特征编码,那么就可以继续通过 WaveRNN 等神经网络声码器将其恢复为语音,从而最终得到带有目标音色的音频。
所以注意力机制到底「注意」的是什么?
陈伟表示,整个注意力机制需要将三种不同的表征信息进行对齐,其中说话人编码器(A)学到的声纹嵌入向量是与时间无关,是基于整段音频学习到的表征矢量,但是对于内容和风格韵律而言,它们与时间相关,不同时间点的表征是不同的。
在时间序列上,模型需要逐帧地解码而生成目标语音。在每一个时间步上,或者说每一步解码上,模型都需要通过注意力机制确定到底要用那些内容、风格与目标说话人声纹进行融合。融合这些信息之后,模型才能完成整个序列的解码,从而生成目标音色对应的语音。
三、想象空间远不止步于输入法
针对语音变声技术在搜狗输入法中的应用,陈伟表示,变声功能上线第一天,使用次数就有数百万次,目前用户使用量在持续增长。在当前上线的目标音色中,林志玲的声音是使用最多的,东北方言、磁性男声等具有特色的嗓音,也非常受欢迎。
他还表示,搜狗输入法除了解决效率问题外,正在不断尝试提升用用户体验,比如这次的搜狗变声,让输入法变得更加有趣好玩。
但搜狗语音变声技术的想象空间远不止如此。
陈伟说,变声能力本质解决两个问题,一个是声音美化(声音滤镜以及音色迁移),一个是隐私保护,这两块有非常大的潜在应用空间,甚至会对行业带来重要的影响。
比如在教育行业,远程直播 / 网络课程非常红火,但是有些老师往往带有口音,普通话并不标准。通过变声技术,可以把网络教师的音色变为一个普通话标准的、更加有品质的音色,同时保留老师自身的内容、风格特色。
再比如未来的内容制作领域,以儿童故事、有声内容为例,假如你拥有蜡笔小新的 IP 版权,结合变声技术就可以以蜡笔小新的口吻讲述小朋友喜欢的故事。
除了教育、有声内容制作外,电商、旅游、宣传等中多领域,变声技术都有用武之地。陈伟也表示,目前公司正在跟一些行业企业接触,未来会走向行业应用。
搜狗语音变声技术,再结合搜狗近期推出的 AI 合成主播,相信与内容制作、教育、娱乐等行业的进一步结合,将会有更大的商用空间有待探索。
(免责声明:以上内容为本网站传播商业信息之目的进行转载发布,不代表本网观点,亦不代表本网站赞同其观点或证实其内容的真实性。)
声明:本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。E-MAIL:dandanxi6@qq.com